> ## Documentation Index
> Fetch the complete documentation index at: https://wb-21fd5541-run-filter-ui-updates.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
> CoreWeave가 관리하는 인프라를 사용해 호스팅된 API 모델을 평가합니다
# 호스팅된 API 모델 평가하기
LLM 평가 작업은 [W\&B Multi-tenant Cloud](/ko/platform/hosting/hosting-options/multi_tenant_cloud)에서 **프리뷰** 기능으로 제공됩니다. 프리뷰 기간에는 컴퓨팅이 무료입니다. [자세히 알아보기](/ko/models/launch#pricing)
이 페이지에서는 CoreWeave가 관리하는 인프라를 사용해 공개적으로 액세스 가능한 URL에 호스팅된 API 모델에서 일련의 평가 벤치마크를 실행하도록 [LLM Evaluation Jobs](/ko/models/launch)을 사용하는 방법을 설명합니다. W\&B Models에 artifact로 저장된 모델 체크포인트를 평가하려면 대신 [모델 체크포인트 평가하기](/ko/models/launch/evaluate-model-checkpoint)를 참조하세요.
## 사전 요구 사항
1. LLM Evaluation Jobs의 [요구 사항 및 제한 사항](/ko/models/launch#more-details)을 검토하세요.
2. 일부 벤치마크를 실행하려면 팀 관리자가 필요한 API 키를 팀 범위 시크릿으로 추가해야 합니다. 평가 작업을 구성할 때는 모든 팀원이 해당 시크릿을 지정할 수 있습니다.
* **OpenAPI API 키**: 점수 산정에 OpenAI 모델을 사용하는 벤치마크에서 사용됩니다. 벤치마크를 선택한 뒤 **Scorer API 키** 필드가 표시되면 필요합니다. 시크릿 이름은 `OPENAI_API_KEY`여야 합니다.
* **Hugging Face 사용자 액세스 토큰**: 하나 이상의 gated Hugging Face 데이터셋에 대한 액세스가 필요한 `lingoly` 및 `lingoly2` 같은 일부 벤치마크에 필요합니다. 벤치마크를 선택한 뒤 **Hugging Face Token** 필드가 표시되면 필요합니다. API 키에는 해당 데이터셋에 대한 액세스 권한이 있어야 합니다. 자세한 내용은 Hugging Face 문서의 [User access tokens](https://huggingface.co/docs/hub/en/security-tokens) 및 [accessing gated datasets](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user)를 참조하세요.
* [Serverless Inference](/ko/inference)에서 제공하는 모델을 평가하려면 조직 관리자 또는 팀 관리자가 아무 값이나 넣어 `WANDB_API_KEY`를 만들어야 합니다. 이 시크릿은 실제 인증에는 사용되지 않습니다.
3. 평가할 모델은 공개적으로 접근 가능한 URL에서 사용할 수 있어야 합니다. 조직 관리자 또는 팀 관리자가 인증용 API 키로 팀 범위 시크릿을 만들어야 합니다.
4. 평가 결과를 위한 새 [W\&B 프로젝트](/ko/models/track/project-page)를 만드세요. 프로젝트 사이드바에서 **Create new project**를 클릭하세요.
5. 각 벤치마크가 어떻게 동작하는지 이해하고 구체적인 요구 사항을 확인하려면 해당 벤치마크 문서를 검토하세요. 편의를 위해 [Available evaluation benchmarks](/ko/models/launch/evaluations) 레퍼런스에 관련 링크가 포함되어 있습니다.
## 모델 평가하기
평가 작업을 설정하고 Launch하려면 다음 단계를 따르세요:
1. W\&B에 로그인한 다음 프로젝트 사이드바에서 **Launch**를 클릭합니다. **LLM Evaluation Jobs** 페이지가 표시됩니다.
2. **Evaluate hosted API model**을 클릭하여 평가를 설정합니다.
3. 평가 결과를 저장할 대상 프로젝트를 선택합니다.
4. **Model** 섹션에서 평가할 베이스 URL과 모델 이름을 지정하고, 인증에 사용할 API 키를 선택합니다. 모델 이름은 [AI Security Institute](https://inspect.aisi.org.uk/providers.html#openai-api)에서 정의한 OpenAI 호환 형식으로 입력하세요. 예를 들어 다음 구문으로 OpenAI 모델을 지정합니다: `openai/`. hosted 모델 provider와 모델의 전체 목록은 [AI Security Institute's model provider 레퍼런스](https://inspect.aisi.org.uk/providers.html)를 참조하세요.
* [Serverless Inference](/ko/inference)에서 제공하는 모델을 평가하려면 베이스 URL을 `https://api.inference.wandb.ai/v1`로 설정하고, 모델 이름을 다음 구문으로 지정합니다: `openai-api/wandb/`. 자세한 내용은 [Inference model catalog](/ko/inference/models)를 참고하세요.
* [OpenRouter](https://inspect.aisi.org.uk/providers.html#openrouter) provider를 사용하려면 다음 구문과 같이 모델 이름 앞에 `openrouter`를 붙입니다: `openrouter/`.
* 맞춤형 OpenAPI 준수 모델을 평가하려면 모델 이름을 다음 구문으로 지정합니다: `openai-api/wandb/`.
5. **Select evaluations**를 클릭한 다음 실행할 벤치마크를 최대 4개까지 선택합니다.
6. 점수 산정에 OpenAI 모델을 사용하는 벤치마크를 선택하면 **Scorer API 키** 필드가 표시됩니다. 이 필드를 클릭한 다음 `OPENAI_API_KEY` 시크릿을 선택합니다. 편의를 위해 팀 관리자는 이 drawer에서 **Create secret**을 클릭해 시크릿을 만들 수 있습니다.
7. Hugging Face의 gated 데이터셋에 대한 액세스가 필요한 벤치마크를 선택하면 **Hugging Face token** 필드가 표시됩니다. [관련 데이터셋에 대한 액세스를 요청한 다음](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user), Hugging Face 사용자 액세스 토큰이 포함된 시크릿을 선택합니다.
8. 필요에 따라 평가할 벤치마크 샘플의 최대 수를 제한하려면 **Sample limit**을 양의 정수로 설정합니다. 그렇지 않으면 작업의 모든 샘플이 포함됩니다.
9. 리더보드를 자동으로 생성하려면 **Publish results to leaderboard**를 클릭합니다. 리더보드에는 모든 평가가 Workspace 패널에 함께 표시되며, 리포트에서도 공유할 수 있습니다.
10. **Launch**를 클릭하여 평가 작업을 시작합니다.
11. 페이지 상단의 원형 화살표 아이콘을 클릭하여 최근 run 모달을 엽니다. 평가 작업은 다른 최근 run과 함께 표시됩니다. 완료된 run의 이름을 클릭하면 단일 run 뷰에서 열리고, **Leaderboard** 링크를 클릭하면 리더보드가 바로 열립니다. 자세한 내용은 [결과 보기](#view-the-results)를 참조하세요.
이 예제 작업은 OpenAI 모델 `o4-mini`에 대해 `simpleqa` 벤치마크를 실행합니다:
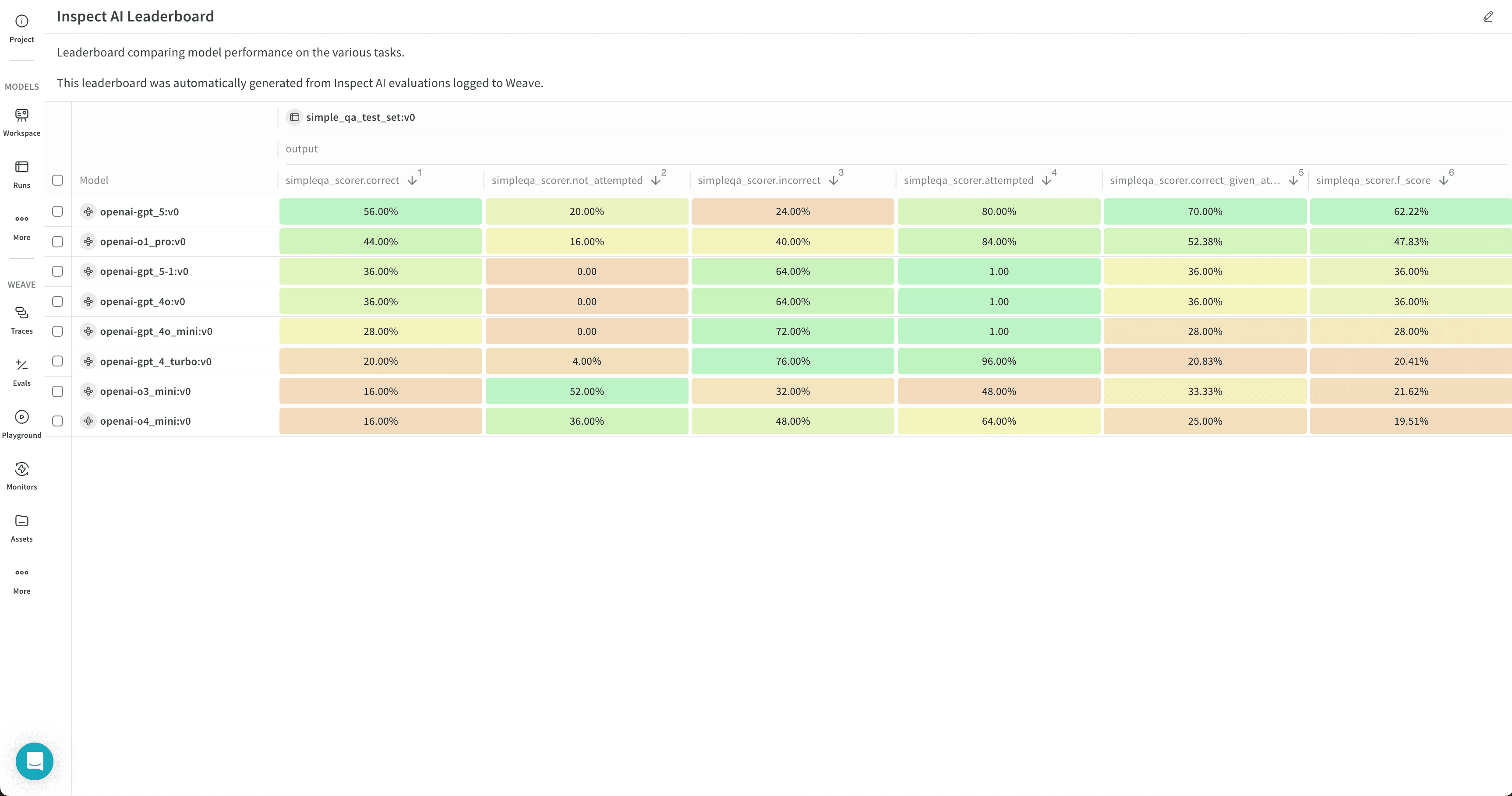
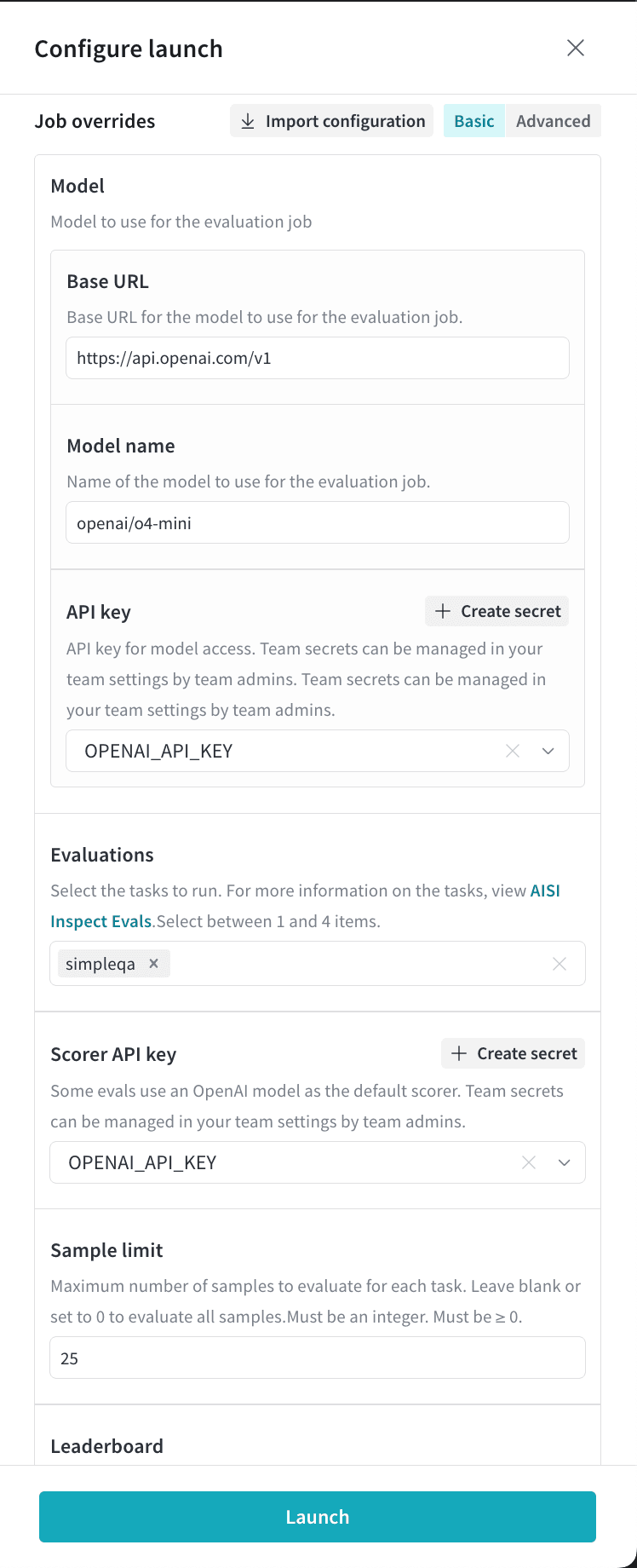 이 예제 리더보드는 여러 OpenAI 모델의 성능을 함께 시각화합니다:
이 예제 리더보드는 여러 OpenAI 모델의 성능을 함께 시각화합니다:
## 평가 결과 검토
대상 프로젝트의 워크스페이스에 있는 W\&B Models에서 평가 작업 결과를 검토합니다.
1. 페이지 상단의 원형 화살표 아이콘을 클릭하여 최근 run 모달을 엽니다. 이 모달에는 평가 작업이 프로젝트의 다른 run과 함께 표시됩니다. 평가 작업에 리더보드가 있으면 **Leaderboard**를 클릭해 리더보드를 전체 화면으로 열거나, run 이름을 클릭해 프로젝트의 단일 run 뷰에서 엽니다.
2. 워크스페이스의 **Evaluations** 섹션 또는 **Weave** 사이드바 패널의 **Traces** 탭에서 평가 작업의 트레이스를 확인합니다.
3. **Overview** 탭을 클릭하여 평가 작업의 설정과 요약 메트릭을 포함한 자세한 정보를 확인합니다.
4. **Logs** 탭을 클릭하여 평가 작업의 디버그 로그를 확인, 검색 또는 다운로드합니다.
5. **Files** 탭을 클릭하여 코드, 로그, 설정 및 기타 출력 파일을 포함한 평가 작업의 파일을 찾아보거나 확인하거나 다운로드합니다.
## 리더보드 사용자 지정하기
리더보드는 지정된 프로젝트로 전송된 모든 평가 작업의 결과를 표시하며, 각 평가 작업의 각 벤치마크마다 한 행씩 표시됩니다. 열에는 트레이스, 입력 값, 출력 값과 같은 평가 작업의 세부 정보가 표시됩니다. 리더보드에 대한 자세한 내용은 [Weave의 리더보드](/ko/weave/guides/core-types/leaderboards)를 참조하세요.
리더보드에서 결과에 대한 피드백을 남기려면 **Feedback** 열에서 이모지 아이콘이나 채팅 아이콘을 클릭하세요.
* 기본적으로 모든 평가 작업이 표시됩니다. 왼쪽의 run 선택기를 사용해 평가 작업을 필터링하거나 검색하세요.
* 기본적으로 평가 작업은 그룹화되지 않습니다. 하나 이상의 열을 기준으로 그룹화하려면 **Group** 아이콘을 클릭하세요. 그룹을 표시하거나 숨길 수 있으며, 그룹을 펼쳐 해당 run을 볼 수 있습니다.
* 기본적으로 모든 오퍼레이션이 표시됩니다. 하나의 오퍼레이션만 표시하려면 **All ops**를 클릭하고 오퍼레이션을 선택하세요.
* 열을 기준으로 정렬하려면 열 헤더를 클릭하세요. 열 표시를 사용자 지정하려면 **Columns**를 클릭하세요.
* 기본적으로 헤더는 단일 수준으로 구성됩니다. 관련 헤더를 함께 묶으려면 헤더 깊이를 늘릴 수 있습니다.
* 개별 열을 선택하거나 선택 해제해 표시하거나 숨길 수 있으며, 한 번의 클릭으로 모든 열을 표시하거나 숨길 수도 있습니다.
* 고정된 열이 고정되지 않은 열보다 먼저 표시되도록 열을 고정할 수 있습니다.
## 리더보드 내보내기
리더보드를 내보내려면 다음 단계를 따르세요.
1. **Columns** 버튼 근처에 있는 다운로드 아이콘을 클릭합니다.
2. 내보내기 크기를 줄이기 위해 기본적으로 트레이스 루트만 내보냅니다. 전체 트레이스를 내보내려면 **Trace roots only**를 끄세요.
3. 내보내기 크기를 줄이기 위해 기본적으로 피드백과 비용은 내보내지 않습니다. 내보내기에 포함하려면 **Feedback** 또는 **Costs**를 켜세요.
4. 기본적으로 JSONL 형식으로 내보냅니다. 형식을 사용자 지정하려면 **Export to file**을 클릭한 다음 형식을 선택하세요.
5. 브라우저에서 리더보드를 내보내려면 **Export**를 클릭하세요.
6. 리더보드를 프로그래밍 방식으로 내보내려면 **Python** 또는 **cURL**을 선택한 다음 **Copy**를 클릭하고 스크립트나 명령어를 실행하세요.
## 평가 작업 다시 실행
상황에 따라 평가 작업을 다시 실행하거나 해당 설정을 확인하는 방법은 여러 가지가 있습니다.
* 마지막으로 실행한 평가 작업을 다시 실행하려면 [모델 평가하기](#evaluate-your-model)의 단계를 따르세요. 대상 프로젝트를 선택하면 이전에 선택한 모델 artifact 세부 정보와 벤치마크가 자동으로 채워집니다. 필요에 따라 조정한 다음 평가 작업을 Launch하세요.
* 프로젝트의 **Runs** 탭 또는 run selector에서 평가 작업을 다시 실행하려면 run 이름 위에 마우스를 올리고 재생 아이콘을 클릭하세요. 설정이 미리 채워진 작업 설정 drawer가 표시됩니다. 필요에 따라 설정을 조정한 다음 **Launch**를 클릭하세요.
* 다른 프로젝트의 평가 작업을 다시 실행하려면 해당 설정을 임포트하세요:
1. [모델 평가하기](#evaluate-your-model)의 단계를 따르세요. 대상 프로젝트를 선택한 후 **설정 임포트**를 클릭하세요.
2. 임포트할 평가 작업이 있는 프로젝트를 선택한 다음 해당 평가 작업 run을 선택하세요. 설정이 미리 채워진 작업 설정 drawer가 표시됩니다.
3. 필요에 따라 설정을 조정하세요.
4. **Launch**를 클릭하세요.
## 평가 작업 설정 내보내기
run의 **Files** 탭에서 평가 작업 설정을 내보냅니다.
1. 단일 run 뷰에서 해당 run을 엽니다.
2. **Files** 탭을 클릭합니다.
3. `config.yaml` 옆의 다운로드 버튼을 클릭해 로컬로 다운로드합니다.