> ## Documentation Index
> Fetch the complete documentation index at: https://wb-21fd5541-run-filter-ui-updates.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# 使用例
> 実践的なコード例で Serverless Inference の使い方を学べます
以下の例では、トレース、評価、比較に Weave と Serverless Inference をどのように使うかを示します。
## 基本例: Llama 3.1 8B を Weave でトレースする
この例では、**Llama 3.1 8B** モデルにプロンプトを送信し、その call を Weave でトレースする方法を示します。トレースでは、LLM call の入力と出力を完全に取得し、パフォーマンスを監視して、Weave UI で結果を分析できます。
[Weave のトレース](/ja/weave/guides/tracking/tracing)の詳細をご覧ください。
この例では、次のことを行います。
* Chat Completion リクエストを行う `@weave.op()` デコレータ付きの関数を定義します
* トレースが記録され、W\&B の entity とプロジェクトにリンクされます
* 関数は自動的にトレースされ、入力、出力、レイテンシ、メタデータがログされます
* 結果はターミナルに出力され、トレースは [https://wandb.ai](https://wandb.ai) の **トレース** タブに表示されます
この例を実行する前に、[前提条件](/ja/inference/prerequisites/)を完了してください。
```python theme={null}
import weave
import openai
# トレース用の Weave チームとプロジェクトを設定する
weave.init("/")
client = openai.OpenAI(
base_url='https://api.inference.wandb.ai/v1',
# https://wandb.ai/settings で API キーを作成する
api_key="",
# オプション: 使用状況トラッキング用のチームとプロジェクト
project="wandb/inference-demo",
)
# Weave でモデルの call をトレースする
@weave.op()
def run_chat():
response = client.chat.completions.create(
model="meta-llama/Llama-3.1-8B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."}
],
)
return response.choices[0].message.content
# トレースされた call を実行してログする
output = run_chat()
print(output)
```
コードを実行したら、次のいずれかの方法で Weave のトレースを表示できます。
1. ターミナルに出力されたリンクをクリックします (例: `https://wandb.ai///r/call/01977f8f-839d-7dda-b0c2-27292ef0e04g`)
2. または、[https://wandb.ai](https://wandb.ai) にアクセスして **トレース** タブを選択します
## 高度な例: Weave 評価とリーダーボードを使用する
モデルのcallのトレースに加えて、パフォーマンスを評価し、リーダーボードを公開することもできます。この例では、質問応答データセット上で2つのモデルを比較します。
この例を実行する前に、[前提条件](/ja/inference/prerequisites/)を完了してください。
```python theme={null}
import os
import asyncio
import openai
import weave
from weave.flow import leaderboard
from weave.trace.ref_util import get_ref
# トレース用の Weave チームとプロジェクトを設定する
weave.init("/")
dataset = [
{"input": "What is 2 + 2?", "target": "4"},
{"input": "Name a primary color.", "target": "red"},
]
@weave.op
def exact_match(target: str, output: str) -> float:
return float(target.strip().lower() == output.strip().lower())
class WBInferenceModel(weave.Model):
model: str
@weave.op
def predict(self, prompt: str) -> str:
client = openai.OpenAI(
base_url="https://api.inference.wandb.ai/v1",
# https://wandb.ai/settings で APIキーを作成する
api_key="",
# オプション: 使用状況トラッキング用のチームとプロジェクト
project="/",
)
resp = client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
)
return resp.choices[0].message.content
llama = WBInferenceModel(model="meta-llama/Llama-3.1-8B-Instruct")
deepseek = WBInferenceModel(model="deepseek-ai/DeepSeek-V3-0324")
def preprocess_model_input(example):
return {"prompt": example["input"]}
evaluation = weave.Evaluation(
name="QA",
dataset=dataset,
scorers=[exact_match],
preprocess_model_input=preprocess_model_input,
)
async def run_eval():
await evaluation.evaluate(llama)
await evaluation.evaluate(deepseek)
asyncio.run(run_eval())
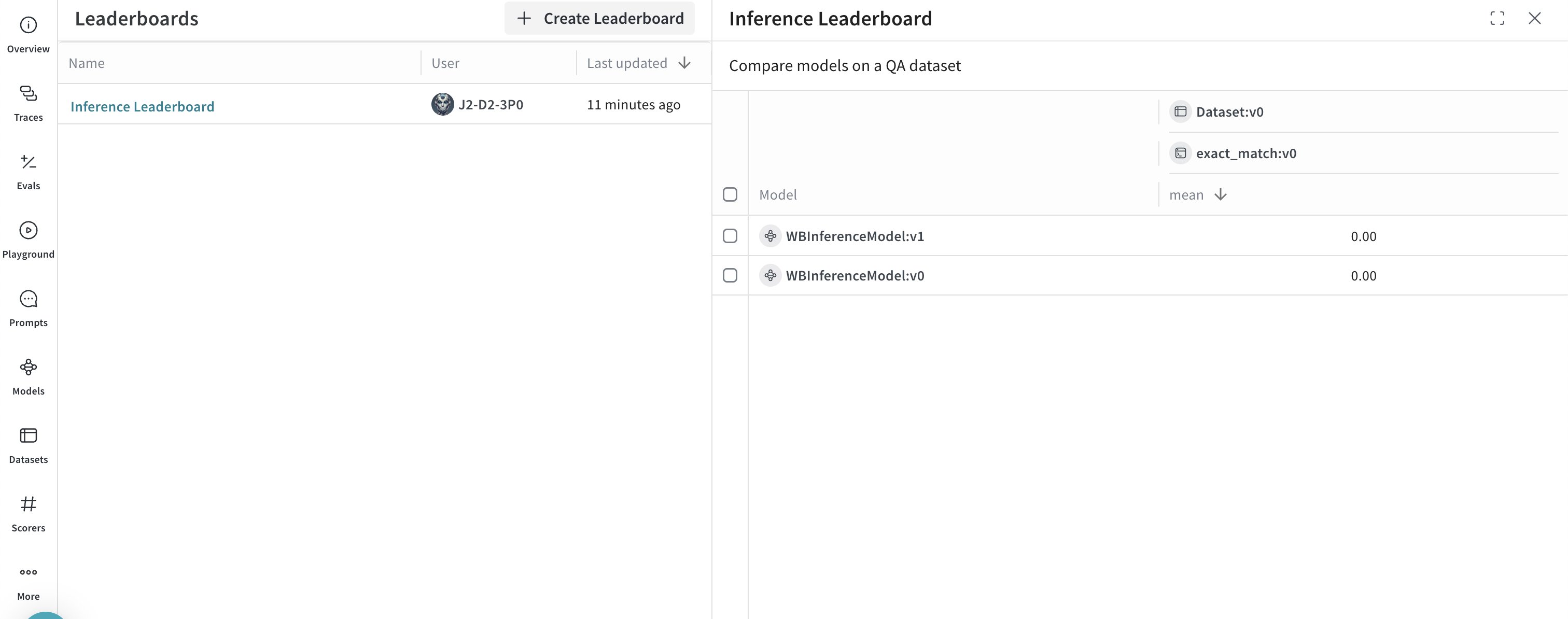
spec = leaderboard.Leaderboard(
name="Inference Leaderboard",
description="Compare models on a QA dataset",
columns=[
leaderboard.LeaderboardColumn(
evaluation_object_ref=get_ref(evaluation).uri(),
scorer_name="exact_match",
summary_metric_path="mean",
)
],
)
weave.publish(spec)
```
このコードを実行したら、[https://wandb.ai/](https://wandb.ai/) の W\&B アカウントにアクセスし、次の操作を行います。
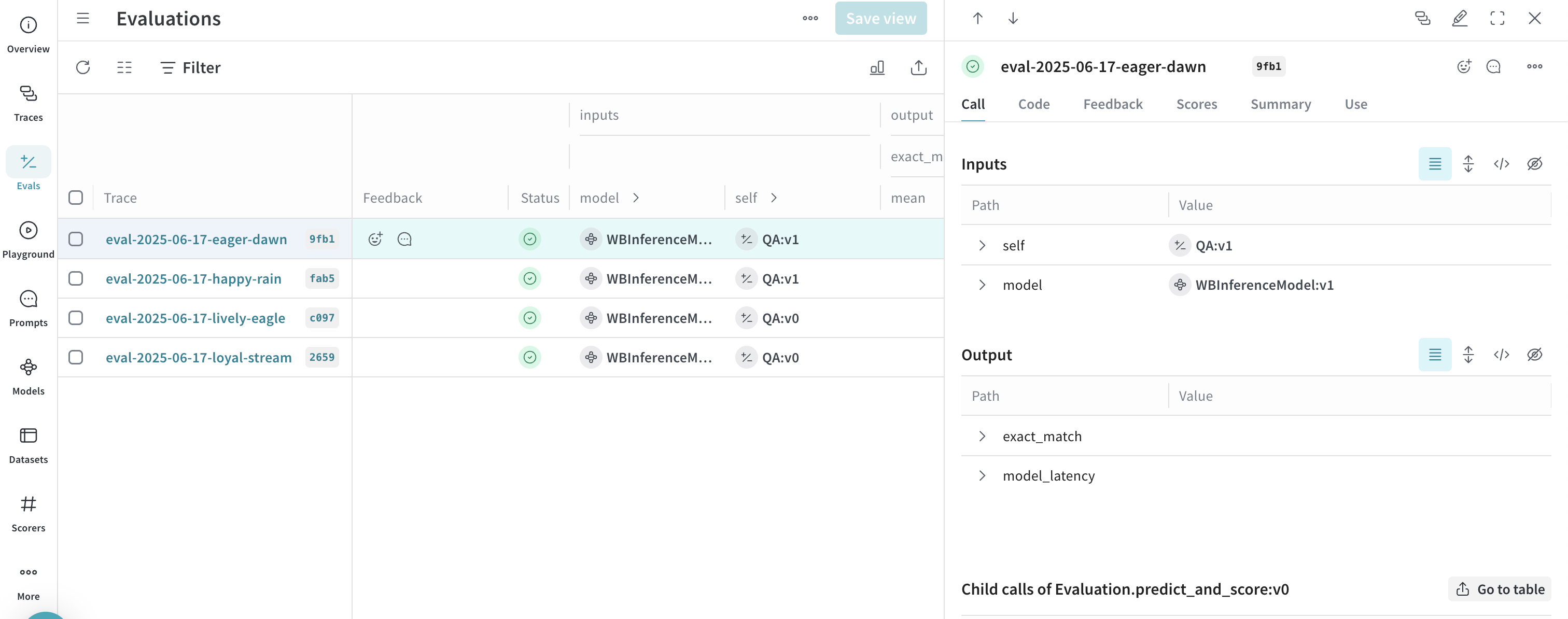
* **トレース** タブを選択して、[トレースを確認します](/ja/weave/guides/tracking/tracing)
* **Evals** タブを選択して、[モデルの評価を確認します](/ja/weave/guides/core-types/evaluations)
* **Leaders** タブを選択して、[生成されたリーダーボードを確認します](/ja/weave/guides/core-types/leaderboards)
## 次のステップ
* 利用可能なすべての method は、[API リファレンス](/ja/inference/api-reference/)で確認してください
* [UI](/ja/inference/ui-guide/)でモデルを試してください