> ## Documentation Index
> Fetch the complete documentation index at: https://wb-21fd5541-run-filter-ui-updates.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Hugging Face Diffusers
> Utilisez l’autologging de W&B avec Hugging Face Diffusers pour suivre les prompts, les médias générés, les configurations et l’architecture du pipeline.
export const ColabLink = ({url}) =>
Essayer sur Colab
;
[Hugging Face Diffusers](https://huggingface.co/docs/diffusers/index) est la bibliothèque de référence pour les modèles de diffusion préentraînés les plus avancés, permettant de générer des images, de l’Audio et même des structures moléculaires 3D. L’intégration W\&B apporte un suivi des expériences riche et flexible, la visualisation des contenus multimédias, l’architecture des pipelines et la gestion de la configuration dans des tableaux de bord centralisés interactifs, sans rien sacrifier à cette simplicité d’utilisation.
## Une journalisation avancée en seulement deux lignes
Consignez tous les prompts, les prompts négatifs, les médias générés et les configurations liés à votre expérience en ajoutant simplement 2 lignes de code. Voici les 2 lignes de code pour commencer la journalisation :
```python theme={null}
# importer la fonction autolog
from wandb.integration.diffusers import autolog
# appeler autolog avant d'appeler le pipeline
autolog(init=dict(project="diffusers_logging"))
```
## Pour commencer
1. Installez `diffusers`, `transformers`, `accelerate` et `wandb`.
* Ligne de commande :
```shell theme={null}
pip install --upgrade diffusers transformers accelerate wandb
```
* Notebook :
```bash theme={null}
!pip install --upgrade diffusers transformers accelerate wandb
```
2. Utilisez `autolog` pour initialiser un run W\&B et suivre automatiquement les entrées et les sorties de [tous les appels de pipeline pris en charge](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72).
Vous pouvez appeler la fonction `autolog()` avec le paramètre `init`, qui accepte un dictionnaire de paramètres requis par [`wandb.init()`](/fr/models/ref/python/functions/init).
Lorsque vous appelez `autolog()`, un run W\&B est initialisé et les entrées ainsi que les sorties de [tous les appels de pipeline pris en charge](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72) sont automatiquement suivies.
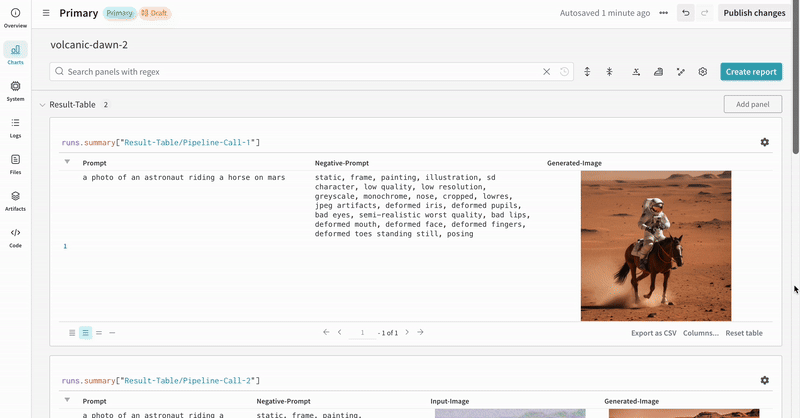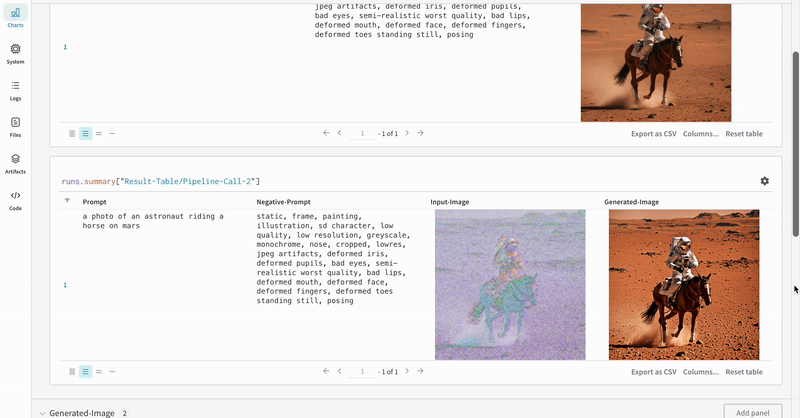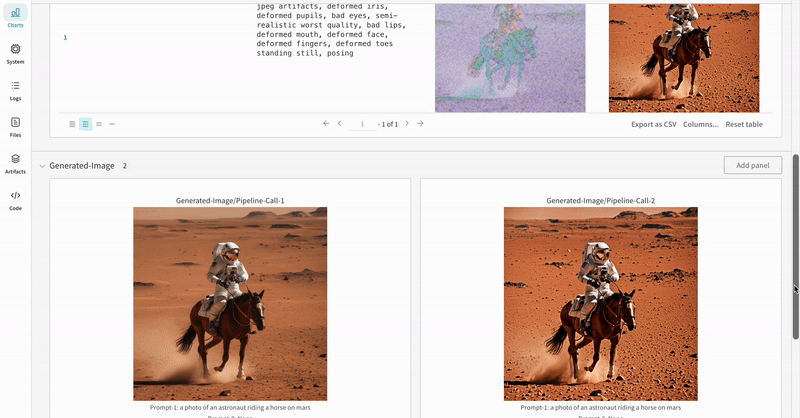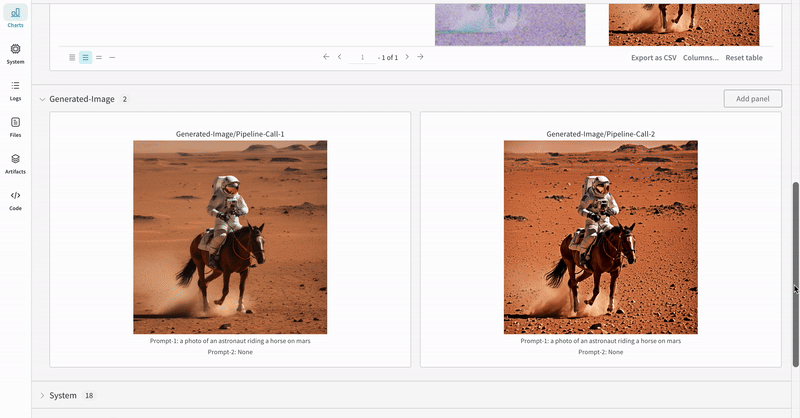
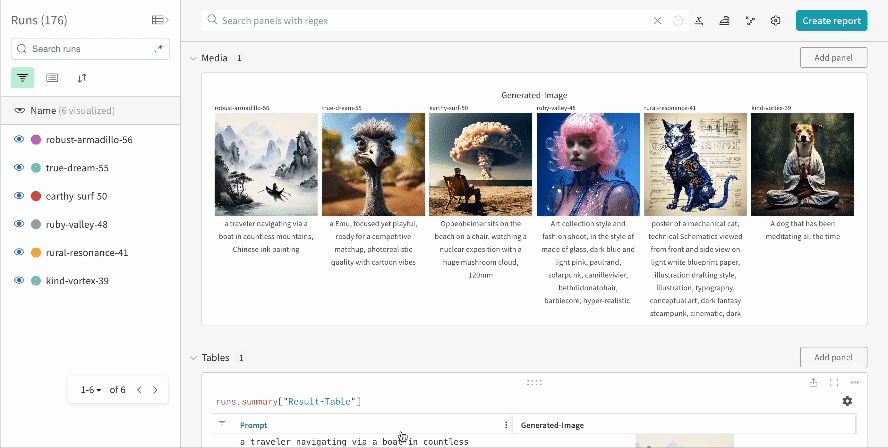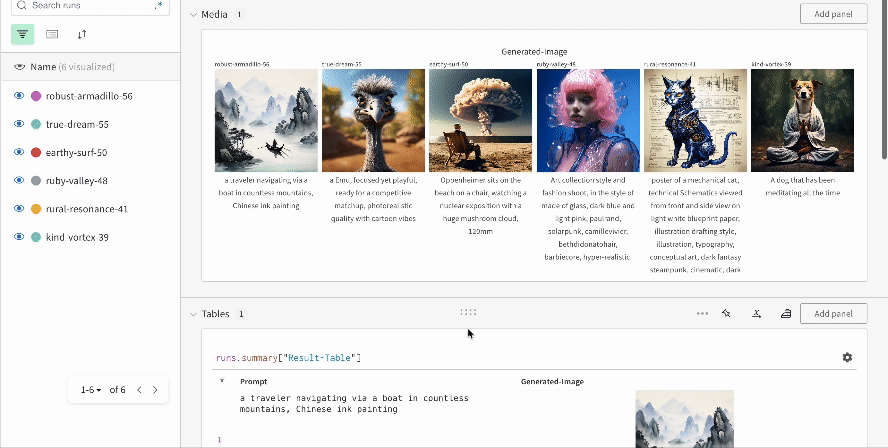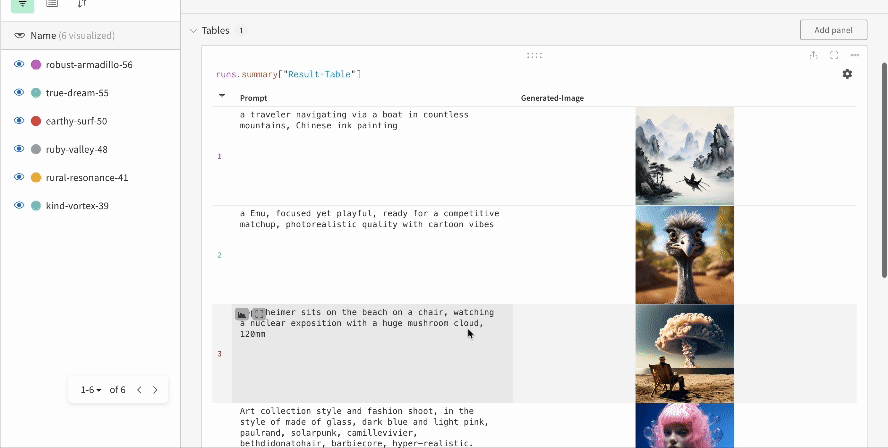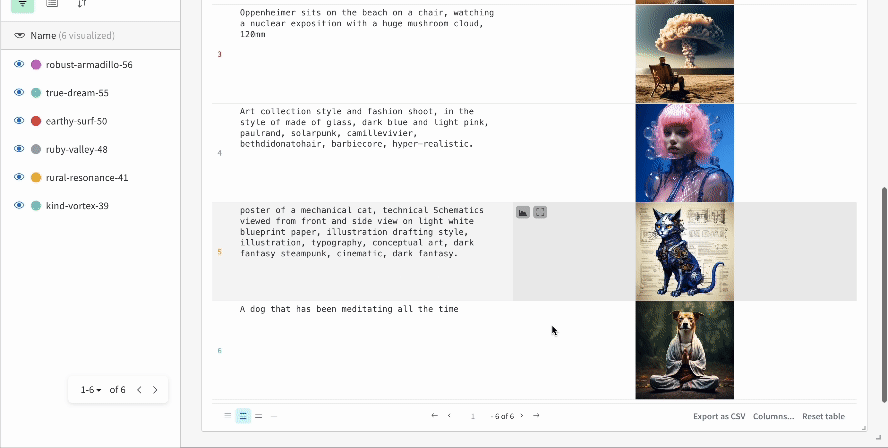
* Chaque appel de pipeline est suivi dans son propre [tableau](/fr/models/tables/) dans le Workspace, et les configurations associées à cet appel sont ajoutées à la liste des flux de travail dans la configuration de ce run.
* Les prompts, les prompts négatifs et les médias générés sont enregistrés dans un [`wandb.Table`](/fr/models/tables/).
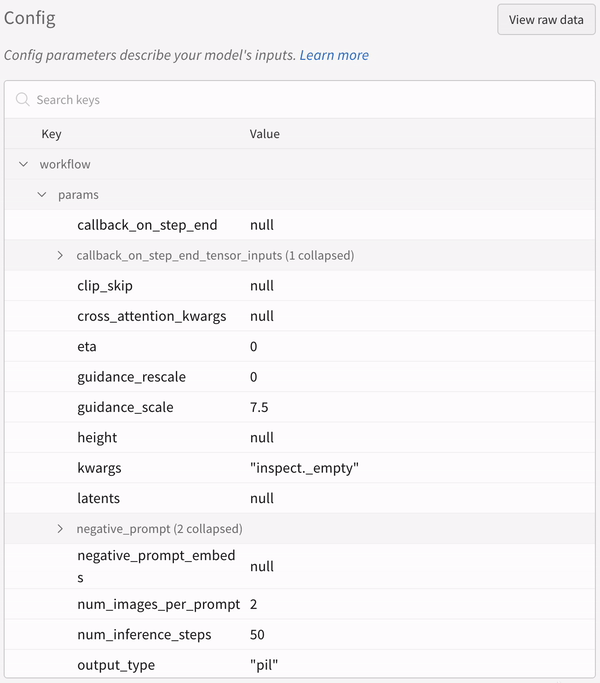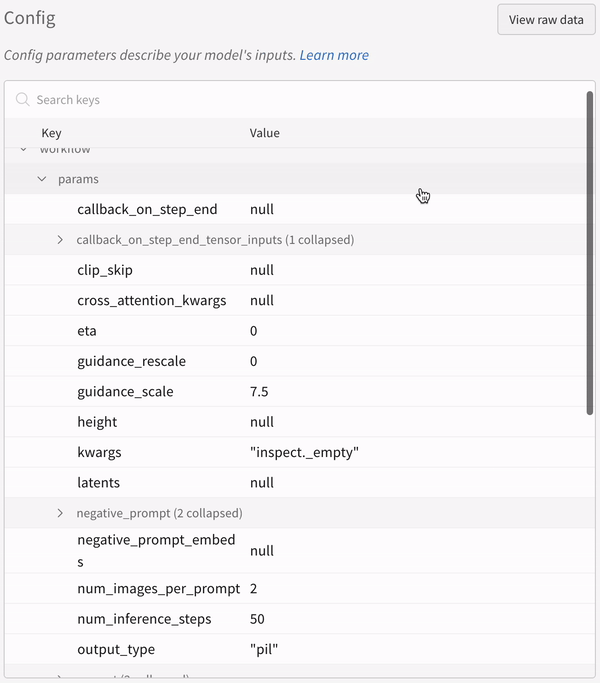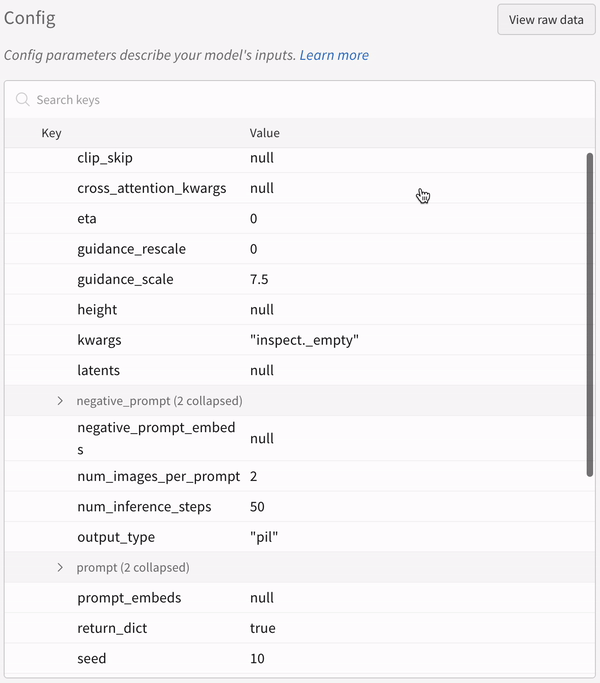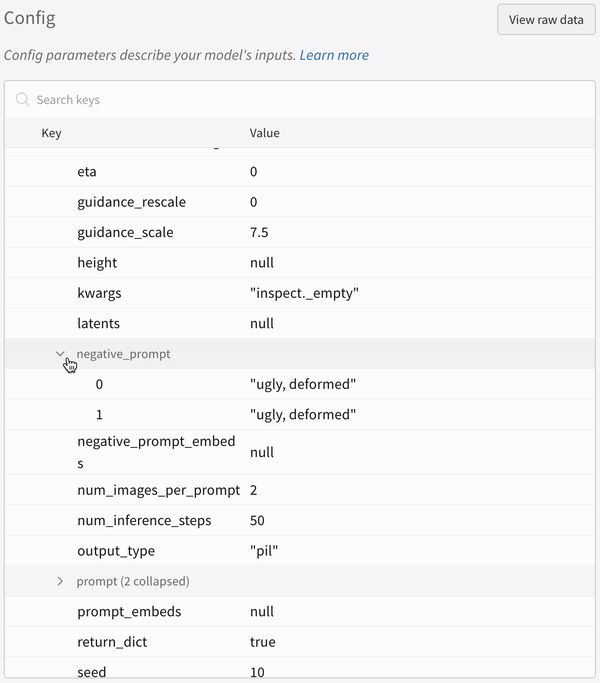
* Toutes les autres configurations associées à l’expérience, y compris la seed et l’architecture du pipeline, sont stockées dans la section de configuration du run.
* Les médias générés pour chaque appel de pipeline sont également enregistrés dans les [panneaux multimédias](/fr/models/track/log/media/) du run.
Vous trouverez une [liste des appels de pipeline pris en charge](https://github.com/wandb/wandb/blob/main/wandb/integration/diffusers/autologger.py#L12-L72). Si vous souhaitez demander une nouvelle fonctionnalité pour cette intégration ou signaler un bug associé, ouvrez une issue sur la [page GitHub issues de W\&B](https://github.com/wandb/wandb/issues).
## Exemples
### Autologging
Voici un bref exemple de bout en bout illustrant autolog en action :
```python theme={null}
import torch
from diffusers import DiffusionPipeline
# importer la fonction autolog
from wandb.integration.diffusers import autolog
# appeler autolog avant d'appeler le pipeline
autolog(init=dict(project="diffusers_logging"))
# Initialiser le pipeline de diffusion
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
# Définir les prompts, les prompts négatifs et la graine
prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# appeler le pipeline pour générer les images
images = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
```
```python theme={null}
import torch
from diffusers import DiffusionPipeline
import wandb
# importer la fonction autolog
from wandb.integration.diffusers import autolog
run = wandb.init()
# appeler autolog avant d'appeler le pipeline
autolog(init=dict(project="diffusers_logging"))
# Initialiser le pipeline de diffusion
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
).to("cuda")
# Définir les prompts, les prompts négatifs et la graine
prompt = ["a photograph of an astronaut riding a horse", "a photograph of a dragon"]
negative_prompt = ["ugly, deformed", "ugly, deformed"]
generator = torch.Generator(device="cpu").manual_seed(10)
# appeler le pipeline pour générer les images
images = pipeline(
prompt,
negative_prompt=negative_prompt,
num_images_per_prompt=2,
generator=generator,
)
# Terminer l'expérience
run.finish()
```
* Les résultats d’une seule expérience :
* Les résultats de plusieurs expériences :
* La configuration d’une expérience :
Vous devez appeler explicitement [`wandb.Run.finish()`](/fr/models/ref/python/functions/finish) lorsque vous exécutez le code dans un environnement de notebook IPython après avoir appelé le pipeline. Cela n’est pas nécessaire lors de l’exécution de scripts Python.
### Suivi des flux de travail à plusieurs pipelines
Cette section illustre l’autolog dans un flux de travail type [Stable Diffusion XL + Refiner](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#base-to-refiner-model), où les variables latentes générées par [`StableDiffusionXLPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl) sont affinées par le refiner correspondant.
```python theme={null}
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
from wandb.integration.diffusers import autolog
# initialiser le pipeline de base SDXL
base_pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
)
base_pipeline.enable_model_cpu_offload()
# initialiser le pipeline de raffinement SDXL
refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base_pipeline.text_encoder_2,
vae=base_pipeline.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner_pipeline.enable_model_cpu_offload()
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# Rendre l'expérience reproductible en contrôlant l'aléatoire.
# La graine sera automatiquement enregistrée dans WandB.
seed = 42
generator_base = torch.Generator(device="cuda").manual_seed(seed)
generator_refiner = torch.Generator(device="cuda").manual_seed(seed)
# Appeler WandB Autolog pour Diffusers. Cela enregistrera automatiquement
# les prompts, les images générées, l'architecture du pipeline et toutes
# les configurations d'expérience associées dans W&B, facilitant ainsi la
# reproduction, le partage et l'analyse de vos expériences de génération d'images.
autolog(init=dict(project="sdxl"))
# Appeler le pipeline de base pour générer les latents
image = base_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
output_type="latent",
generator=generator_base,
).images[0]
# Appeler le pipeline de raffinement pour générer l'image affinée
image = refiner_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
image=image[None, :],
generator=generator_refiner,
).images[0]
```
```python theme={null}
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline, StableDiffusionXLPipeline
import wandb
from wandb.integration.diffusers import autolog
run = wandb.init()
# initialiser le pipeline de base SDXL
base_pipeline = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
)
base_pipeline.enable_model_cpu_offload()
# initialiser le pipeline de raffinement SDXL
refiner_pipeline = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base_pipeline.text_encoder_2,
vae=base_pipeline.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner_pipeline.enable_model_cpu_offload()
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "static, frame, painting, illustration, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, deformed toes standing still, posing"
# Rendre l'expérience reproductible en contrôlant l'aléatoire.
# La graine sera automatiquement enregistrée dans WandB.
seed = 42
generator_base = torch.Generator(device="cuda").manual_seed(seed)
generator_refiner = torch.Generator(device="cuda").manual_seed(seed)
# Appeler WandB Autolog pour Diffusers. Cela enregistrera automatiquement
# les prompts, les images générées, l'architecture du pipeline et toutes
# les configurations d'expérience associées dans W&B, facilitant ainsi la
# reproduction, le partage et l'analyse de vos expériences de génération d'images.
autolog(init=dict(project="sdxl"))
# Appeler le pipeline de base pour générer les latents
image = base_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
output_type="latent",
generator=generator_base,
).images[0]
# Appeler le pipeline de raffinement pour générer l'image affinée
image = refiner_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
image=image[None, :],
generator=generator_refiner,
).images[0]
# Terminer l'expérience
run.finish()
```
* Exemple d'expérience Stable Diffusion XL + Refiner :
## Autres ressources
* [Guide de l’ingénierie des prompts pour Stable Diffusion](https://wandb.ai/geekyrakshit/diffusers-prompt-engineering/reports/A-Guide-to-Prompt-Engineering-for-Stable-Diffusion--Vmlldzo1NzY4NzQ3)
* [PIXART-α : un modèle Transformer de diffusion pour la génération d’images à partir de texte](https://wandb.ai/geekyrakshit/pixart-alpha/reports/PIXART-A-Diffusion-Transformer-Model-for-Text-to-Image-Generation--Vmlldzo2MTE1NzM3)
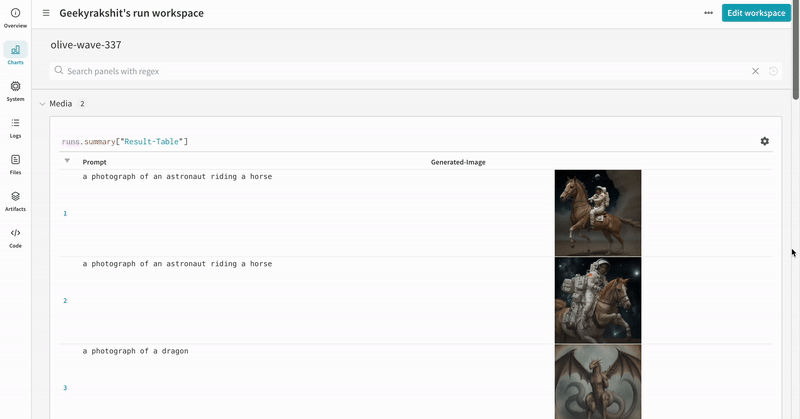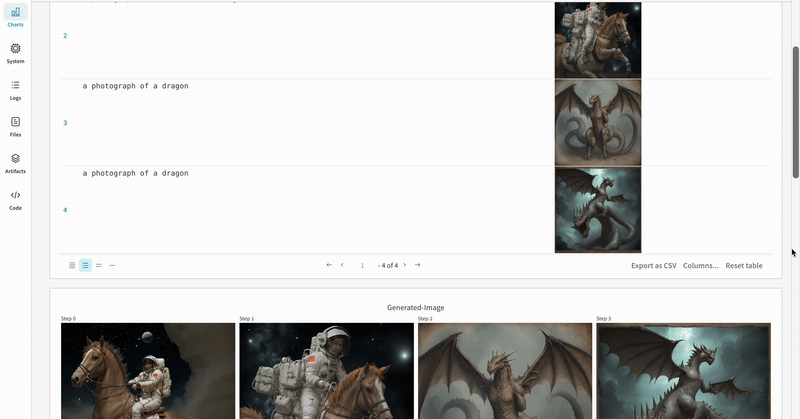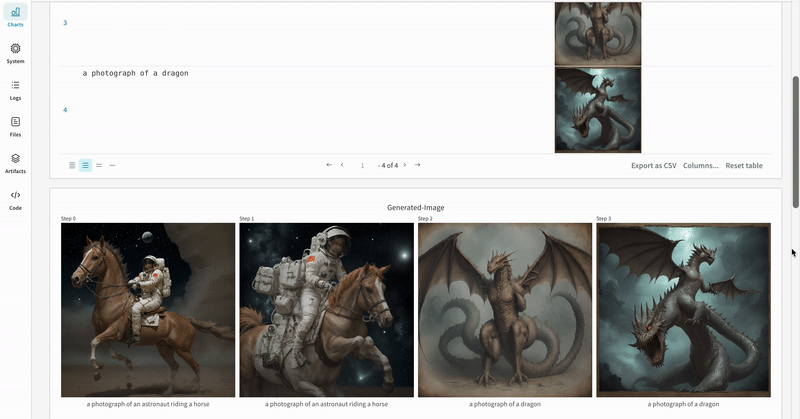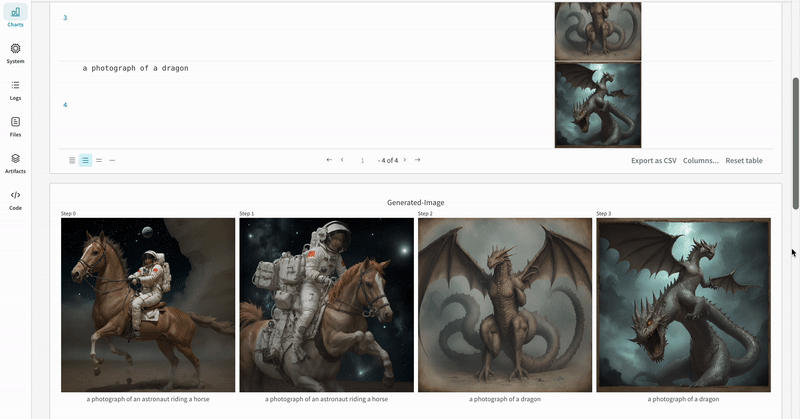
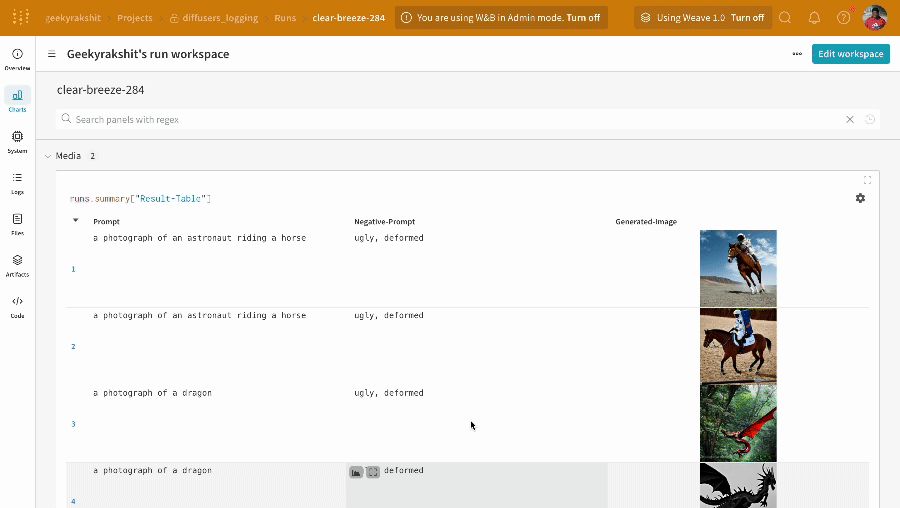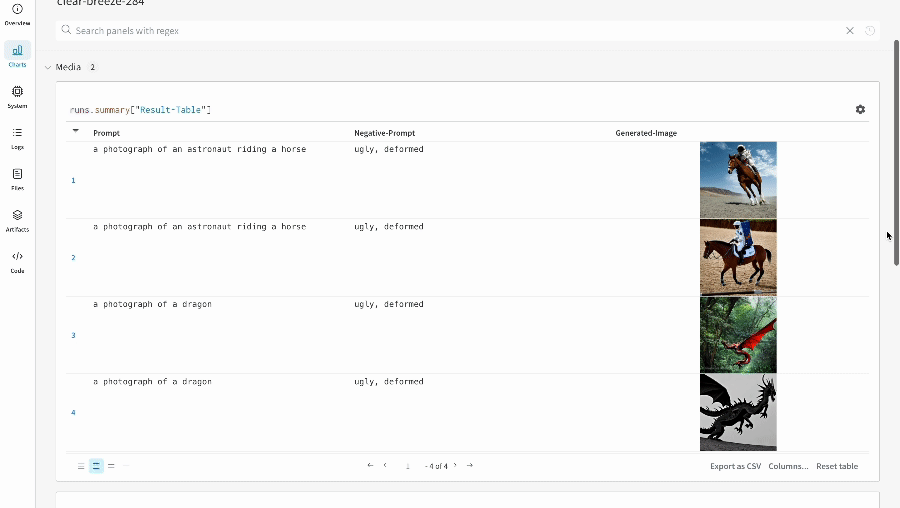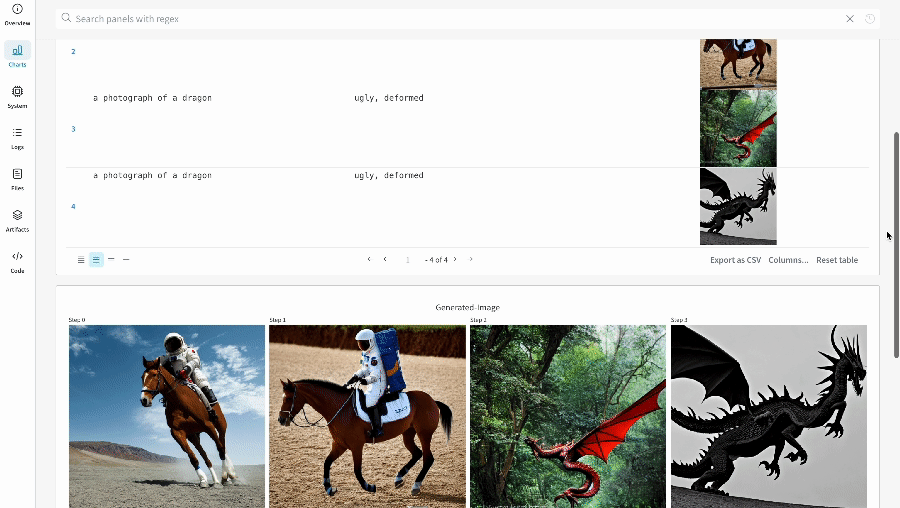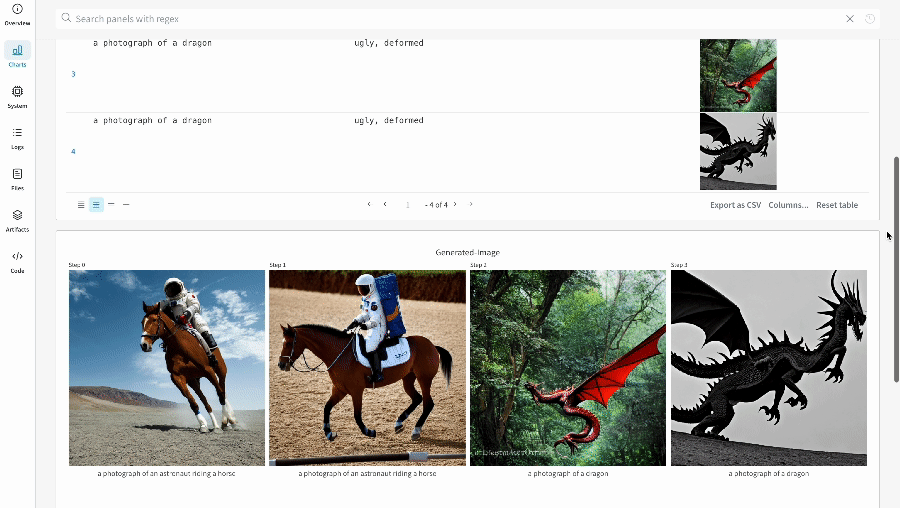 * Les résultats de plusieurs expériences :
* Les résultats de plusieurs expériences :
 * La configuration d’une expérience :
* La configuration d’une expérience :